Sometimes we might need convert categorical feature into multiple binary features. Such situation emerged while I was implementing decision tree with independent categorical variable using python sklearn.tree for the post Building Decision Trees in Python – Handling Categorical Data and it turned out that a text independent variable is not supported.
One of solution would be binary encoding, also called one-hot-encoding when we might code [‘red’,’green’,’blue’] with 3 columns, one for each category, having 1 when the category match and 0 otherwise. [1]
Here we implement the python code that makes such binary encoding. The script looks at text data column and add numerical columns with values 0 or 1 to the original data. If category word exists in the column then it will be 1 in the column for this category, otherwise 0.
The list of categories is initialized in the beginning of the script. Additionally we initialize data source file, number of column with text data, and number of first empty column on right side. The script will add columns on right side starting from first empty column.
The next step in the script is to navigate through each row and do binary conversion and update data.
Below is some example of added binary columns to data input .
Below is full source code.
# -*- coding: utf-8 -*-
import pandas as pd
words = ["adwords", "adsense","mortgage","money","loan"]
data = pd.read_csv('adwords_data5.csv', sep= ',' , header = 0)
total_rows = len(data.index)
y_text_column_index=7
y_column_index=16
for index, w in enumerate(words):
data[w] = 0
col_index=data.columns.get_loc(w)
for x in range (total_rows):
if w in data.iloc[x,y_text_column_index] :
data.iloc[x,y_column_index+index]=1
else :
data.iloc[x,y_column_index+index]=0
print (data)
In the post Building Decision Trees in Python we looked at the decision tree with numerical continuous dependent variable. This type of decision trees can be called also regression tree.
But what if we need to use categorical dependent variable? It is still possible to create decision tree and in this post we will look how to create decision tree if dependent variable is categorical data. In this case the decision tree is called classification tree. Classification trees, as the name implies are used to separate the dataset into classes belonging to the response variable. [4] Classification is a typical problem that can be found in such fields as machine learning, predictive analytics, data mining.
Getting Data
For simplicity we will use the same dataset as before but will convert numerical target variable into categorical variable as we want build python code for decision tree with categorical dependent variable.
To convert dependent variable into categorical we use the following simple rule:
if CPC < 22 then CPC = "Low"
else CPC = “High”
For independent variables we will use “keyword” and “number of words” fields.
Keyword (usually it is several words) is a categorical variable. In general it is not the problem as in either case (regression or classification tree), the predictors or independent variables may be categorical or numeric. It is the target variable that determines the type of decision tree needed.[4]
However sklearn.tree (at least the version that is used here) does not support categorical independent variable. See discussion and suggestions on stack overflow [5]. To use independent categorical variable, we will code the categorical feature into multiple binary features. For example, we might code [‘red’,’green’,’blue’] with 3 columns, one for each category, having 1 when the category match and 0 otherwise. This is called one-hot-encoding, binary encoding, one-of-k-encoding or whatever. [5]
Below are shown few rows from the table data. We added 2 columns for categories “insurance”, “Adsense”. We actually have more categories and therefore we added more columns but this is not shown in the table.
A decision tree is a decision support tool that uses a tree-like graph or model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility. It is one way to display an algorithm.
Decision trees are commonly used in operations research, specifically in decision analysis, to help identify a strategy most likely to reach a goal, but are also a popular tool in machine learning. [1]
Decision trees are widely used since they are easy to interpret, handle categorical features, extend to the multiclass classification setting, do not require feature scaling, and are able to capture non-linearities and feature interactions. [2] Decision trees are also one of the most widely used predictive analytics techniques.
Recently I decided to build python code for decision tree for AdWords data. This was motivated by the post [3] about visual analytics used for AdWords dataset. Below are the main components that I used for implementing decision tree.
Dataset
AdWords dataset – the dataset was obtained on Internet. Below is the table with few rows to show data. Only the columns that were used for decision tree, are shown in the table.
Keyword
Number of words
CPC
Clicks
CTR
Cost
Impressions
car insurance premium
3
176
7
0.012
1399
484
AdSense data
2
119
13
0.025
1061
466
The following independent variables were selected:
Number of words in keyword phrase – this column was added based on the keyword phrase column.
CTR – click through rate
For the dependent variable it was selected CPC – Average Cost per Click.
Python Module
As the dependent variable is numeric and continuos, the regression decision tree from python module sklearn.tree was used in the script:
from sklearn.tree import DecisionTreeRegressor
In sklearn.tree Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features. [5]
Visualization
For visualization of decision tree graphviz was installed. “Graphviz is open source graph visualization software. Graph visualization is a way of representing structural information as diagrams of abstract graphs and networks. It has important applications in networking, bioinformatics, software engineering, database and web design, machine learning, and in visual interfaces for other technical domains.”
Python Script
The created code consisted of the following steps:
reading data from csv data file
selecting needed columns
splitting dataset for testing and training
initializing DecisionTreeRegressor
visualizing decision tree via function. Note that the path to Graphviz are specified inside of scripts.
Decision tree and Python code are shown below. Online resources used for this post are provided in the reference section.
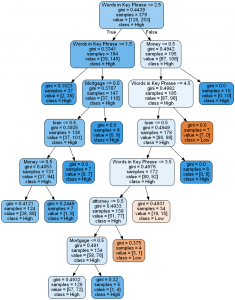
Decision Tree
Python computer code:
# -*- coding: utf-8 -*-
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.tree import DecisionTreeRegressor
import subprocess
from sklearn.tree import export_graphviz
def visualize_tree(tree, feature_names):
with open("dt.dot", 'w') as f:
export_graphviz(tree, out_file=f, feature_names=feature_names, filled=True, rounded=True )
command = ["C:\\Program Files (x86)\\Graphviz2.38\\bin\\dot.exe", "-Tpng", "C:\\Users\\Owner\\Desktop\\A\\Python_2016_A\\dt.dot", "-o", "dt.png"]
try:
subprocess.check_call(command)
except:
exit("Could not run dot, ie graphviz, to "
"produce visualization")
data = pd.read_csv('adwords_data.csv', sep= ',' , header = 1)
X = data.values[:, [3,13]]
Y = data.values[:,11]
X_train, X_test, y_train, y_test = train_test_split( X, Y, test_size = 0.3, random_state = 100)
clf = DecisionTreeRegressor( random_state = 100,
max_depth=3, min_samples_leaf=4)
clf.fit(X_train, y_train)
visualize_tree(clf, ["Words in Key Phrase", "CTR"])
To calculate normalized data, the below table was built.
min 4.3 2 1 0.1
max 7.9 4.4 6.9 2.5
max-min 3.6 2.4 5.9 2.4
Here min, max and min-max are taken over the columns of iris data set which are:
1. sepal length in cm
2. sepal width in cm
3. petal length in cm
4. petal width in cm


You must be logged in to post a comment.