In the previous posts [1,2] I created script for machine learning stock market price on next day prediction. But it was pointed by readers that in stock market prediction, it is more important to know the trend: will the stock go up or down. So I updated the script to predict difference between today and yesterday prices. If it is negative the stock price will go down, if positive it will go up. Below will be described implemented modifications.
Data inputting
Data from previous days are entered as features through additional columns. The number of columns can be changed through parameter N in the beginning of script. So for example for day 20 the input will contain data for day 21 as target and data for days 20, 19,18,17… 20-N
Also added differencing before scaling. Differencing helped to improve performance of network. It also makes easy to get changes from previous day. In the end the differenced data inverted back.
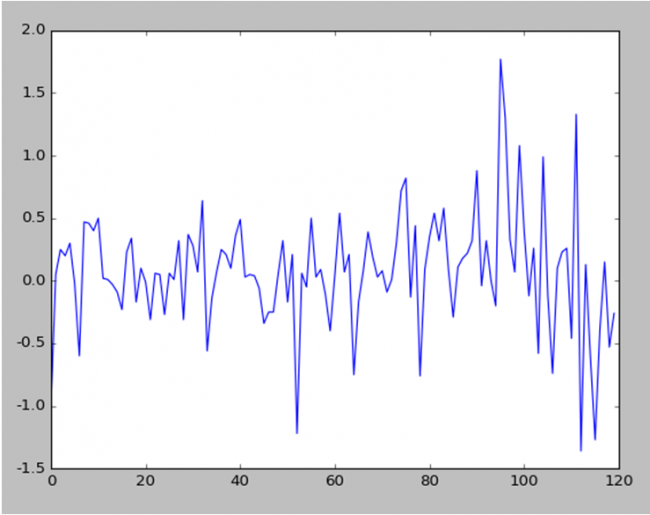
Below is the stock data prices after applying differencing (subtructing previous day stock data price from current day)
Predicting future changes
I used moving_test_window_preds function. Inside of this function the script within loop is adding new prediction to “moving window” array and removing first element from it. This is based on example from blog post on forecasting time series with LSTM[4].
So the script is predicting future day data based on the previous known data in the “moving window”, updating known data and starting again. The performance evaluated by comparing predicted data with test (not used before) data.
LSTM Configuration
The LSTM network is constructed as following:
model = Sequential () input_shape =(len(cols), 1) )) model.add (LSTM ( 400, activation = 'relu', inner_activation = 'hard_sigmoid' , bias_regularizer=L1L2(l1=0.01, l2=0.01), input_shape =(len(cols), 1), return_sequences = False )) model.add(Dropout(0.3)) from keras import optimizers model.add (Dense (output_dim =1, activation = 'linear', activity_regularizer=regularizers.l1(0.01))) adam=optimizers.Adam(lr=0.01, beta_1=0.89, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=True) model.compile (loss ="mean_squared_error" , optimizer = "adam") history=model.fit (x_train, y_train, batch_size =1, nb_epoch =1400, shuffle = False, validation_split=0.15)
Weight regularization together with differencing helped to decrease overfitting.
Results
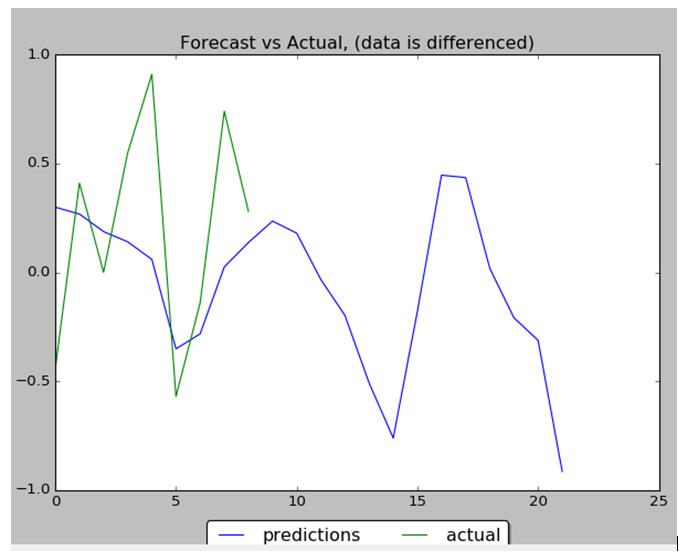
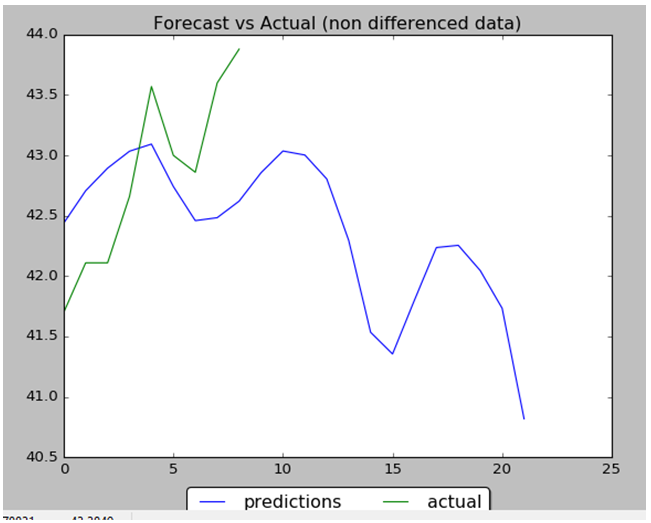
Performance of NN is 88% : 8 correct data out of 9. Below are the data charts that comparing predicted data (9 first days from 22 total days) with actual test data. Below you can find output chart and full python source code.
import numpy as np
import pandas as pd
from sklearn import preprocessing
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
from keras.regularizers import L1L2
fname="C:\\Users\\Leo\\Desktop\\A\\WS\\stock data analysis 2017\\GM.csv"
data_csv = pd.read_csv (fname)
#how many data we will use
# (should not be more than dataset length )
data_to_use= 150
# number of training data
# should be less than data_to_use
train_end =120
total_data=len(data_csv)
#most recent data is in the end
#so need offset
start=total_data - data_to_use
yt = data_csv.iloc [start:total_data ,4] #Close price
yt_ = yt.shift (-1)
print (yt_)
data = pd.concat ([yt, yt_], axis =1)
data. columns = ['yt', 'yt_']
N=18
cols =['yt']
for i in range (N):
data['yt'+str(i)] = list(yt.shift(i+1))
cols.append ('yt'+str(i))
data = data.dropna()
data_original = data
data=data.diff()
data = data.dropna()
# target variable - closed price
# after shifting
y = data ['yt_']
x = data [cols]
scaler_x = preprocessing.MinMaxScaler ( feature_range =( -1, 1))
x = np. array (x).reshape ((len( x) ,len(cols)))
x = scaler_x.fit_transform (x)
scaler_y = preprocessing. MinMaxScaler ( feature_range =( -1, 1))
y = np.array (y).reshape ((len( y), 1))
y = scaler_y.fit_transform (y)
x_train = x [0: train_end,]
x_test = x[ train_end +1:len(x),]
y_train = y [0: train_end]
y_test = y[ train_end +1:len(y)]
x_train = x_train.reshape (x_train. shape + (1,))
x_test = x_test.reshape (x_test. shape + (1,))
from keras.models import Sequential
from keras.layers.core import Dense
from keras.layers.recurrent import LSTM
from keras.layers import Dropout
from keras import optimizers
from numpy.random import seed
seed(1)
from tensorflow import set_random_seed
set_random_seed(2)
from keras import regularizers
model = Sequential ()
model.add (LSTM ( 400, activation = 'relu', inner_activation = 'hard_sigmoid' , bias_regularizer=L1L2(l1=0.01, l2=0.01), input_shape =(len(cols), 1), return_sequences = False ))
model.add(Dropout(0.3))
model.add (Dense (output_dim =1, activation = 'linear', activity_regularizer=regularizers.l1(0.01)))
adam=optimizers.Adam(lr=0.01, beta_1=0.89, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=True)
model.compile (loss ="mean_squared_error" , optimizer = "adam")
history=model.fit (x_train, y_train, batch_size =1, nb_epoch =1400, shuffle = False, validation_split=0.15)
y_train_back=scaler_y.inverse_transform (np. array (y_train). reshape ((len( y_train), 1)))
plt.figure(1)
plt.plot (y_train_back)
fmt = '%.1f'
tick = mtick.FormatStrFormatter(fmt)
ax = plt.axes()
ax.yaxis.set_major_formatter(tick)
print (model.summary())
print(history.history.keys())
plt.figure(2)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
fmt = '%.1f'
tick = mtick.FormatStrFormatter(fmt)
ax = plt.axes()
ax.yaxis.set_major_formatter(tick)
score_train = model.evaluate (x_train, y_train, batch_size =1)
score_test = model.evaluate (x_test, y_test, batch_size =1)
print (" in train MSE = ", round( score_train ,4))
print (" in test MSE = ", score_test )
pred1 = model.predict (x_test)
pred1 = scaler_y.inverse_transform (np. array (pred1). reshape ((len( pred1), 1)))
prediction_data = pred1[-1]
model.summary()
print ("Inputs: {}".format(model.input_shape))
print ("Outputs: {}".format(model.output_shape))
print ("Actual input: {}".format(x_test.shape))
print ("Actual output: {}".format(y_test.shape))
print ("prediction data:")
print (prediction_data)
y_test = scaler_y.inverse_transform (np. array (y_test). reshape ((len( y_test), 1)))
print ("y_test:")
print (y_test)
act_data = np.array([row[0] for row in y_test])
fmt = '%.1f'
tick = mtick.FormatStrFormatter(fmt)
ax = plt.axes()
ax.yaxis.set_major_formatter(tick)
plt.figure(3)
plt.plot( y_test, label="actual")
plt.plot(pred1, label="predictions")
print ("act_data:")
print (act_data)
print ("pred1:")
print (pred1)
plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.05),
fancybox=True, shadow=True, ncol=2)
fmt = '$%.1f'
tick = mtick.FormatStrFormatter(fmt)
ax = plt.axes()
ax.yaxis.set_major_formatter(tick)
def moving_test_window_preds(n_future_preds):
''' n_future_preds - Represents the number of future predictions we want to make
This coincides with the number of windows that we will move forward
on the test data
'''
preds_moving = [] # Store the prediction made on each test window
moving_test_window = [x_test[0,:].tolist()] # First test window
moving_test_window = np.array(moving_test_window)
for i in range(n_future_preds):
preds_one_step = model.predict(moving_test_window)
preds_moving.append(preds_one_step[0,0])
preds_one_step = preds_one_step.reshape(1,1,1)
moving_test_window = np.concatenate((moving_test_window[:,1:,:], preds_one_step), axis=1) # new moving test window, where the first element from the window has been removed and the prediction has been appended to the end
print ("pred moving before scaling:")
print (preds_moving)
preds_moving = scaler_y.inverse_transform((np.array(preds_moving)).reshape(-1, 1))
print ("pred moving after scaling:")
print (preds_moving)
return preds_moving
print ("do moving test predictions for next 22 days:")
preds_moving = moving_test_window_preds(22)
count_correct=0
error =0
for i in range (len(y_test)):
error=error + ((y_test[i]-preds_moving[i])**2) / y_test[i]
if y_test[i] >=0 and preds_moving[i] >=0 :
count_correct=count_correct+1
if y_test[i] < 0 and preds_moving[i] < 0 :
count_correct=count_correct+1
accuracy_in_change = count_correct / (len(y_test) )
plt.figure(4)
plt.title("Forecast vs Actual, (data is differenced)")
plt.plot(preds_moving, label="predictions")
plt.plot(y_test, label="actual")
plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.05),
fancybox=True, shadow=True, ncol=2)
print ("accuracy_in_change:")
print (accuracy_in_change)
ind=data_original.index.values[0] + data_original.shape[0] -len(y_test)-1
prev_starting_price = data_original.loc[ind,"yt_"]
preds_moving_before_diff = [0 for x in range(len(preds_moving))]
for i in range (len(preds_moving)):
if (i==0):
preds_moving_before_diff[i]=prev_starting_price + preds_moving[i]
else:
preds_moving_before_diff[i]=preds_moving_before_diff[i-1]+preds_moving[i]
y_test_before_diff = [0 for x in range(len(y_test))]
for i in range (len(y_test)):
if (i==0):
y_test_before_diff[i]=prev_starting_price + y_test[i]
else:
y_test_before_diff[i]=y_test_before_diff[i-1]+y_test[i]
plt.figure(5)
plt.title("Forecast vs Actual (non differenced data)")
plt.plot(preds_moving_before_diff, label="predictions")
plt.plot(y_test_before_diff, label="actual")
plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.05),
fancybox=True, shadow=True, ncol=2)
plt.show()
References
1. Time Series Prediction with LSTM and Keras for Multiple Steps Ahead
2. Machine Learning Stock Prediction with LSTM and Keras
3. Data File
4. Using LSTMs to forecast time-series
Hi owygs156,
I think I’m running into some problems, the differenced forecast plot is just a flat line, it does predict any movements.
Any thoughts about what it could be?
Thanks