In the previous posts [1],[2] perl was used to get content from the web through Faroo API and Guardian APIs. In this post PHP and Pyhton will be used to get web data using same APIs.
PHP has a powerful JSON parsing mechanism, which, because PHP is a dynamic language, enables PHP developers to program against a JSON object graph in a very straightforward way. [3] In the PHP example code shown here we do not need any additional library or module in PHP script while Perl code required some modules such as LWP, HTTP, JSON.
Below is PHP code example to make API call to search function and display web title and link for returned results. You can also see online running example of PHP API script
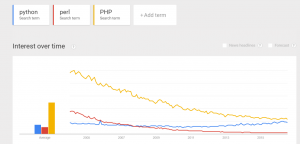
Python is a widely used powerful programming language. It’s extremely popular in data science, machine learning and bioinformatics. Many websites are built around the Django Python framework. Below is the comparison of trends over the 10+ years for Python, PHP and Perl. Trend for Python, Perl, PHP
Data Source: Google Trends (www.google.com/trends).”
And here is the python code to make API call and display data for returned results. The example was developed and tested on Anaconda/Spider(Python 3.5) environment.
import requests
resp=requests.get("http://www.faroo.com/api?q=analytics&start=1&l=en&src=web&f=json&key=xxxx&jsoncallback=?")
if resp.status_code != 200:
print ("Something went wrong")
exit();
message=resp.json().get('results')
# to see in plain text all results enable next line
# print (message)
print ("\n\n\n")
for item in message:
#to see everything related to item enable next line
#print (item)
print (item['url'])
print (item['title'])
print (item['kwic'])
print ("\n\n")
In one of the previous post http://intelligentonlinetools.com/blog/2016/05/28/using-python-for-mining-data-from-twitter/ python source code for mining Twitter data was implemented. Clustering was applied to put tweets in different groups using bag of words representation for the text. The results of clustering were obtained via numerical matrix. Now we will look at visualization of clustering results using python. Also we will do some additional data cleaning before clustering.
Data preprocessing
The following actions are added before clustering :
Retweet tweets always start with text in the form “RT @name: “. The code is added to remove this text.
Special characters like #, ! are removed.
URL links are removed.
All numerical numbers also removed.
Duplicates tweets retweets are removed – we keep only one tweet
Below is the code for the above preprocessing steps. See full source code for functions right, remove_duplicates.
for counter, t in enumerate(texts):
if t.startswith("rt @"):
pos= t.find(": ")
texts[counter] = right(t, len(t) - (pos+2))
for counter, t in enumerate(texts):
texts[counter] = re.sub(r'[?|$|.|!|#|\-|"|\n|,|@|(|)]',r'',texts[counter])
texts[counter] = re.sub(r'https?:\/\/.*[\r\n]*', '', texts[counter], flags=re.MULTILINE)
texts[counter] = re.sub(r'[0|1|2|3|4|5|6|7|8|9|:]',r'',texts[counter])
texts[counter] = re.sub(r'deeplearning',r'deep learning',texts[counter])
texts= remove_duplicates(texts)
Plotting
The vector-space models as a choosen model for representing word meanings in this example is the problem in multidimensional space. The number of different words is high even for small set of data. There is however a tool t-SNE to visualize high-dimensional data. It converts similarities between data points to joint probabilities and tries to minimize the Kullback-Leibler divergence between the joint probabilities of the low-dimensional embedding and the high-dimensional data. t-SNE has a cost function that is not convex, i.e. with different initializations we can get different results. [1] Below is the python source code for building plot for visualization of clustering results.
from sklearn.manifold import TSNE
model = TSNE(n_components=2, random_state=0)
np.set_printoptions(suppress=True)
Y=model.fit_transform(train_data_features)
plt.scatter(Y[:, 0], Y[:, 1], c=clustering_result, s=290,alpha=.5)
plt.show()
The resulting visualization is shown below Data Visualization for Clustering Results
Analysis
Additionally to visualization the silhouette_score was computed and the obtained value was around 0.2
The silhouette_score gives the average value for all the samples. This gives a perspective into the density and separation of the formed clusters.
Silhoette coefficients (as these values are referred to as) near +1 indicate that the sample is far away from the neighboring clusters. A value of 0 indicates that the sample is on or very close to the decision boundary between two neighboring clusters and negative values indicate that those samples might have been assigned to the wrong cluster. [2]
Thus in this post python script for visualization of clustering results was provided. The clustering was applied to results of Twitter search for some specific phrase.
It should be noted that clustering of tweets data is challenging as the tweet length can be only 140 characters or less. Such problems are related to short text clustering and there are some additional technique that can be applied to get better results. [3]-[6]
Below is the full script code.
import twitter
import json
import matplotlib.pyplot as plt
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.cluster import Birch
from sklearn.manifold import TSNE
import re
from sklearn.metrics import silhouette_score
# below function is from
# http://www.dotnetperls.com/duplicates-python
def remove_duplicates(values):
output = []
seen = set()
for value in values:
# If value has not been encountered yet,
# ... add it to both list and set.
if value not in seen:
output.append(value)
seen.add(value)
return output
# below 2 functions are from
# http://stackoverflow.com/questions/22586286/
# python-is-there-an-equivalent-of-mid-right-and-left-from-basic
def left(s, amount = 1, substring = ""):
if (substring == ""):
return s[:amount]
else:
if (len(substring) > amount):
substring = substring[:amount]
return substring + s[:-amount]
def right(s, amount = 1, substring = ""):
if (substring == ""):
return s[-amount:]
else:
if (len(substring) > amount):
substring = substring[:amount]
return s[:-amount] + substring
CONSUMER_KEY ="xxxxxxx"
CONSUMER_SECRET ="xxxxxxx"
OAUTH_TOKEN = "xxxxxx"
OAUTH_TOKEN_SECRET = "xxxxxx"
auth = twitter.oauth.OAuth (OAUTH_TOKEN, OAUTH_TOKEN_SECRET, CONSUMER_KEY, CONSUMER_SECRET)
twitter_api= twitter.Twitter(auth=auth)
q='#deep learning'
count=100
# Do search for tweets containing '#deep learning'
search_results = twitter_api.search.tweets (q=q, count=count)
statuses=search_results['statuses']
# Iterate through 5 more batches of results by following the cursor
for _ in range(5):
print ("Length of statuses", len(statuses))
try:
next_results = search_results['search_metadata']['next_results']
except KeyError:
break
# Create a dictionary from next_results
kwargs=dict( [kv.split('=') for kv in next_results[1:].split("&") ])
search_results = twitter_api.search.tweets(**kwargs)
statuses += search_results['statuses']
# Show one sample search result by slicing the list
print (json.dumps(statuses[0], indent=10))
# Extracting data such as hashtags, urls, texts and created at date
hashtags = [ hashtag['text'].lower()
for status in statuses
for hashtag in status['entities']['hashtags'] ]
urls = [ urls['url']
for status in statuses
for urls in status['entities']['urls'] ]
texts = [ status['text'].lower()
for status in statuses
]
created_ats = [ status['created_at']
for status in statuses
]
# Preparing data for trending in the format: date word
i=0
print ("===============================\n")
for x in created_ats:
for w in texts[i].split(" "):
if len(w)>=2:
print (x[4:10], x[26:31] ," ", w)
i=i+1
# Prepare tweets data for clustering
# Converting text data into bag of words model
vectorizer = CountVectorizer(analyzer = "word", \
tokenizer = None, \
preprocessor = None, \
stop_words='english', \
max_features = 5000)
for counter, t in enumerate(texts):
if t.startswith("rt @"):
pos= t.find(": ")
texts[counter] = right(t, len(t) - (pos+2))
for counter, t in enumerate(texts):
texts[counter] = re.sub(r'[?|$|.|!|#|\-|"|\n|,|@|(|)]',r'',texts[counter])
texts[counter] = re.sub(r'https?:\/\/.*[\r\n]*', '', texts[counter], flags=re.MULTILINE)
texts[counter] = re.sub(r'[0|1|2|3|4|5|6|7|8|9|:]',r'',texts[counter])
texts[counter] = re.sub(r'deeplearning',r'deep learning',texts[counter])
texts= remove_duplicates(texts)
train_data_features = vectorizer.fit_transform(texts)
train_data_features = train_data_features.toarray()
print (train_data_features.shape)
print (train_data_features)
vocab = vectorizer.get_feature_names()
print (vocab)
dist = np.sum(train_data_features, axis=0)
# For each, print the vocabulary word and the number of times it
# appears in the training set
for tag, count in zip(vocab, dist):
print (count, tag)
# Clustering data
n_clusters=7
brc = Birch(branching_factor=50, n_clusters=n_clusters, threshold=0.5, compute_labels=True)
brc.fit(train_data_features)
clustering_result=brc.predict(train_data_features)
print ("\nClustering_result:\n")
print (clustering_result)
# Outputting some data
print (json.dumps(hashtags[0:50], indent=1))
print (json.dumps(urls[0:50], indent=1))
print (json.dumps(texts[0:50], indent=1))
print (json.dumps(created_ats[0:50], indent=1))
with open("data.txt", "a") as myfile:
for w in hashtags:
myfile.write(str(w.encode('ascii', 'ignore')))
myfile.write("\n")
# count of word frequencies
wordcounts = {}
for term in hashtags:
wordcounts[term] = wordcounts.get(term, 0) + 1
items = [(v, k) for k, v in wordcounts.items()]
print (len(items))
xnum=[i for i in range(len(items))]
for count, word in sorted(items, reverse=True):
print("%5d %s" % (count, word))
for x in created_ats:
print (x)
print (x[4:10])
print (x[26:31])
print (x[4:7])
plt.figure(1)
plt.title("Frequency of Hashtags")
myarray = np.array(sorted(items, reverse=True))
plt.xticks(xnum, myarray[:,1],rotation='vertical')
plt.plot (xnum, myarray[:,0])
plt.show()
model = TSNE(n_components=2, random_state=0)
np.set_printoptions(suppress=True)
Y=model.fit_transform(train_data_features)
print (Y)
plt.figure(2)
plt.scatter(Y[:, 0], Y[:, 1], c=clustering_result, s=290,alpha=.5)
for j in range(len(texts)):
plt.annotate(clustering_result[j],xy=(Y[j][0], Y[j][1]),xytext=(0,0),textcoords='offset points')
print ("%s %s" % (clustering_result[j], texts[j]))
plt.show()
silhouette_avg = silhouette_score(train_data_features, clustering_result)
print("For n_clusters =", n_clusters, "The average silhouette_score is :", silhouette_avg)

You must be logged in to post a comment.