
What is Planning Process
Planning is the process of finding a sequence of actions (steps), which if executed by an
agent result in the achievement of a set of predefined goals. The sequence of actions mentioned above is also referred to as plan. Planning is studied within Reinforcement Learning and Automated Planning that are subfields of Machine Learning and Artificial Intelligence. [1]
Planning can be used in production, here [5] you can find reinforcement learning example applied to learn an approximately optimal strategy for controlling the stations of a production line in order to meet the demand. The goal in this thesis was to create schedule for machines such as press and oven, running in production environment.
In our day to day life we do planning without using any knowledge about Reinforcement Learning or Artificial Intelligence. For example when we create plan of actions for completion project or plan of tasks for the week or month. Using Reinforcement Learning for planning we can save time, find better strategies, eliminate human error.
In this post we will look at typical planning problem of finding actions needed to complete some specific tasks. This is very practical problem as it can be used for making our everyday schedule or for achieving our goals.
Combining Q Learning with Dyna
We will investigate how to apply Reinforcement Learning for planning of actions to complete tasks using algorithm Dyna-Q proposed by R. Sutton and based on combining Dyna and Q learning.
Dyna is most common and often used solution to speed up the learning procedure in Reinforcement Learning. [2],[3] In our experiment we will see how it impact on speed.
Under Dyna the action taken is computed rapidly as a function of the situation, but the
mapping implemented by that system is continually adjusted by a planning process and the planner is not restricted to planning about the current situation. [2]
Q-learning is a model free method which means that there is no need to maintain a separate
structure for the value function and the policy but only the Q-value function. The Dyna-Q
architecture is simpler as two data structures have been replaced with one. [1]
We will look at more details of Dyna-Q framework after we define our environment and problem.
Problem Description
As mentioned above we will do planning of actions that are needed to complete tasks. Given some goals and set of actions we are interesting to know what action we need to take now in order to get the best result in the end.
Lets say by the end of week I need complete project in Applied Machine Learning and project in Reinforcement Learning. I have some rewards for completion of each project as 3 and 10. This means that completion of Reinforcement Learning is more important for whatever reason.
Lets assume I need to put specific number of time – 2 and 3 time units to complete end goal for each project. Time unit can be just 1 hour for this example. I am working only in the evening each day and each day I can make only one action. I have only 5 times to pick.
While I need to put only 2 units of time to complete my weekly goal on Machine Learning project, I still can work on this project after putting 2 unit of time, possibly doing something for next week or for extra credit. Reward is calculated only in the end of week.
The diagram of one of possible path would look like this:

On this diagram the green indicates path that produces the max reward 13 as the agent was able to complete both goals.
Simplification
As this is the first post on reinforcement learning for planning, we pick very simple problem. And even without calculations we can say that the optimal schedule is when we allocate 2 units for ML project and 3 units for another project and our maximum reward can be 13.
Thus in this example we did few simplifications:
the number of actions is the same as the number of goals. This makes easy a little bit programming for now.
The number of time units needed to complete task is not changing. This is not always true. In real situation we often realize that something that we planned, will take longer time or may be not possible at all at the current moment.
Despite of the above simplification, the program still has a lot to learn.
How would it create action plan for completion the given tasks by the end of specific time period?
Solution
The code here is based on dyna-q for maze problem[4]. It has 2 modules for programming environment and Reinforcement Learning algorithm. Additionally it has main module which run loop with episods.
Our solution consists of two parts:
1. Reinforcement Learning Q learning where we use observed value and update the table with state, action, reward. Here we create action.
2. Dyna part – where we do simulations and also update state action reward after each simulation. Basically we choose randomly state and action, define next state and reward and update the table in same way as in 1.
Out table is pandas data frame shown on flowchart on right side.
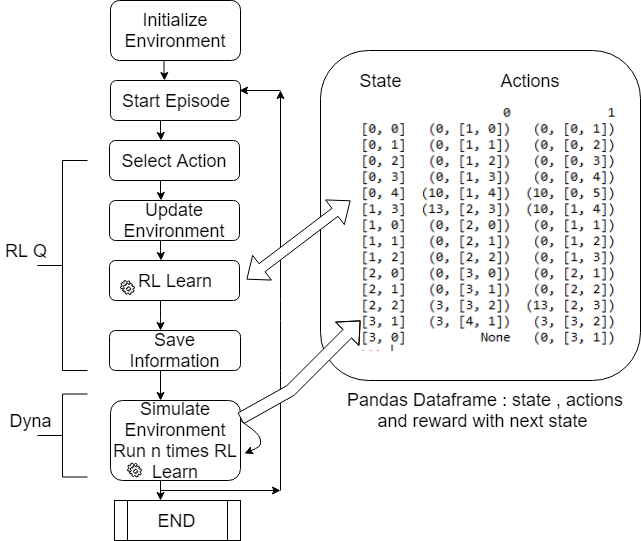
To run this reinforcement learning example you can use python source code from the links below:
Reinforcement Learning Dyna-Q Planning Environment
Reinforcement Learning Dyna-Q
Reinforcement Learning Dyna-Q Run Planning
Results
We run 3 different agents:
1. Random Agent – action is always picked randomly
2. RL Agent – we use only observed values, no simulations are performed. So we use only Q learning.
3. Dyna Q – we use Q learning and Dyna simulations.
The results are shown on charts below. Here we output average reward for each 50 episods.

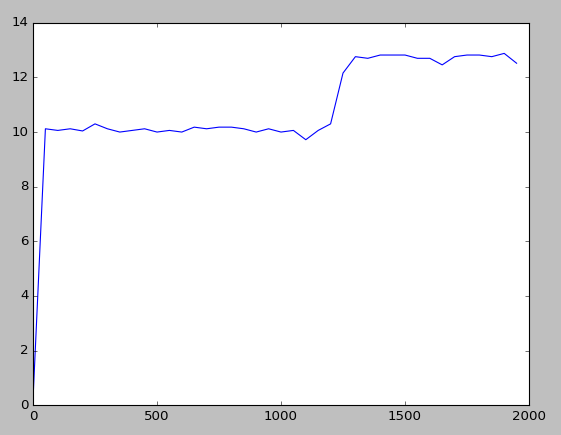

The random agent was not able to understand that there is better option with reward 13.
RL agent performed better than random, was able to pick reward at 13 however it took long way.
Dyna Q agent was able to pick reward 13 after only 100 episods. The average however about 12.5 So there is some room for improvement.
Still it is not bad considering that we did not do any specific tune up of parameters.
Next Steps
We learned algorithms for reinforcement learning such as Q learning and Dyna-Q techniques that can be used for planning. By adding Dyna part the learning was significantly accelerated.
Next actions would be improve performance, use reinforcement learning deep learning net and make more general environment setup.
References
1. Reinforcement Learning and Automated Planning: A Survey
2. Planning by Incremental Dynamic Programming R. S. Sutton
3. Dyna
4. Reinforcement Learning Methods and Tutorials
5. Reinforcement learning for planning of a simulated production line Gustaf Ehn, Hugo Werner February 27, 2018