Convolutional neural networks(CNN) is increasingly important concept in computer science and finds more and more applications in different fields. Many posts on the web are about applying convolutional neural networks for image classification as CNN is very useful type of neural networks for image classification. But convolutional neural networks can also be used for applications other than images, such as time series prediction. This post is reviewing existing papers and web resources about applying CNN for forecasting time series data. Some resources also contain python source code.
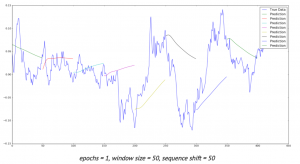
Deep neural networks opened new opportunities for time series prediction. New types of neural networks such as LSTM (variant of the RNN), CNN were applied for time series forecasting. For example here is the link for predicting time series with LSTM. [1] You can find here also the code. The code provides nice graph with ability to compare actual data and predicted data. (See figure below, sourced from [1]) Predictions start at different points of time so you can see and compare performance for several predictions.
Below review is showing different approaches that can be used for forecasting time series data with convolutional neural networks.
1. Raw Data
The simplest way to feed data into neural network is to use raw data. Here is the link [2] to results of experiments with different types of neural networks including CNN. In this study stock data such as Date,Open,High,Low,Close,Volume,Adj Close were used with 3 types of networks: MLP, CNN and RNN.
CNN architecture was used as 2-layer convolutional neural network (combination of convolution and max-pooling layers) with one fully-connected layer. To improve performance the author suggests using different features (not only scaled time series) like some technical indicators, volume of sales.
According to [12] it is common to periodically insert a Pooling layer in-between successive Convolution layers in a CNN architecture. Its function is to progressively reduce the spatial size of the representation to reduce the amount of parameters and computation in the network, and hence to also control overfitting. The Pooling Layer operates independently on every depth slice of the input and resizes it spatially, using the MAX operation.
2. Automatic Selection of Features
Transforming data before inputting to neural network is common practice. We can use feature based methods like described here in Feature-selection-time-series-forecasting-python or filtering methods like removing trend, seasonality or low pass / high pass filtering.
With deep learning it is possible to lean features automatically. For example in one research the authors introduce a deep learning framework for multivariate time series classification: Multi-Channels Deep Convolutional Neural Networks (MCDCNN). Multivariate time series are separated into univariate ones and perform feature learning on each univariate series individually. Then a
normal MLP is concatenated at the end of feature learning to do classification. [3]
The CNN architecture consists of 2 layer CNN (combination of filter, activation and pooling layers) and 2 Fully connected layers that represent classification MLP.
3. Fully Convolutional Neural Network (FCN)
In this study different neural network architectures such as Multilayer Perceptrons, Fully convolutional NN (FCN), Residual Network are proposed. For FCN authors build the final networks by stacking three convolution blocks with the filter sizes {128, 256, 128} in each block. Unlike the MCNN and MC-CNN, any pooling operation is excluded. This strategy helps to prevent overfitting. Batch normalization is applied to speed up the convergence speed and help improve generalization.
After the convolution blocks, the features are fed into a global average pooling layer instead of a fully connected layer, which largely reduces the number of weights. The final label is produced by a softmax layer. [4] Thus the architecture of neural network consists of three convolution blocks and global average pooling and softmax layers in the end.
4. Different Data Transformations
In this study [5] CNNs were trained with different data transformations, which included: the entire dataset, spatial clustering, and PCA decomposition. Data was also fit to the hidden modules of a Clockwork Recurrent Neural Network. This type of recurrent network (CRNN) has the advantage of maintaining a high-temporal-resolution memory in its hidden layers after training.
This network also overcomes the problem of the vanishing gradient found in other RNNs by partitioning the neurons in its hidden layers as different ”sub-clocks” that are able to capture the input to the network at different time steps. Here you can find more about CRNN [11]. According to this paper a clockwork RNN architecture is similar to a simple RNN with an input, output and hidden layer. The hidden layer is partitioned into g modules each with its own clock rate. Within each module the neurons are fully interconnected.
5. Analysing Multiple Time Series Relationships
This paper [6] focuses on analyzing multiple time series relationships such as correlations between them. Authors show that deep learning methods for time series processing are comparable to the other approaches and have wide opportunities for further improvement. Range of methods is discussed and code optimisations is applied for the convolutional neural network for the forecasting time series data domain.
6. Data Augmentation
In this study two approaches are proposed to artificially increase the size of training sets. The first one is based on data-augmentation techniques. The second one consists in mixing different training sets and learning the network in a semi-supervised way. The authors show that these two approaches improve the overall classification performance.
7. Encoding data as image
Another methodology for time series with convolutional neural networks that got popular with deep learning is encoding data as the image. Here data is encoded as images which feed to neural network. This enables the use of techniques from computer vision for classification.
Here [8] is the link where python script can be found for encoding data as image. It encodes data into formats such as GAF, MTF. The script has the dependencies on python modules such as Numpy, Pandas, Matplolib and Cpickle.
Theory of using image encoded data is described in [9]. In this paper a novel framework proposes to encode time series data as different types of images, namely, Gramian Angular Fields (GAF) and Markov Transition Fields (MTF).
Learning Traffic as Images:
This paper [10] proposes a convolutional neural network (CNN)-based method that learns traffic as images and predicts large-scale, network-wide traffic speed with a high accuracy. Spatiotemporal traffic dynamics are converted to images describing the time and space relations of traffic flow via a two-dimensional time-space matrix. A CNN is applied to the image following two consecutive steps: abstract traffic feature extraction and network-wide traffic speed prediction. CNN architecture consists of several convolutional and pooling layers and fully connected layer in the end for prediction.
Conclusion
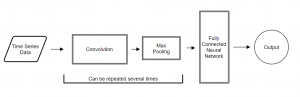
Deep learning and convolutional neural networks created new opportunities for forecasting time series data domain. The above text presents different techniques that can be used in time series prediction with convolutional neural networks. The common part that we can see in most of studies is that feature extraction can be done via deep learning automatically in CNN or in other words, CNNs can learn features on their own. Below you can see architecture of CNN at very high level. The actual implementations can vary in different ways, some of them were shown above.
References
1. LSTM NEURAL NETWORK FOR TIME SERIES PREDICTION
2. Neural networks for algorithmic trading. Part One — Simple time series forecasting
3. Time Series Classification Using Multi-Channels Deep Convolutional Neural Networks
4. Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline
5. Assessing Neuroplasticity with Convolutional and Recurrent Neural Networks
6. Signal Correlation Prediction Using Convolutional Neural Networks
7. Data Augmentation for Time Series Classification using Convolutional Neural Networks.
8. Imaging-time-series-to-improve-classification-and-imputation
9. Encoding Time Series as Images for Visual Inspection and Classification Using
Tiled Convolutional Neural Networks
10. Learning Traffic as Images: A Deep Convolutional Neural Network for Large-Scale Transportation Network Speed Prediction
11. A Clockwork RNN
12. CS231n Convolutional Neural Networks for Visual Recognition


You must be logged in to post a comment.