According to survey [1] Decision Trees constitute one of the 10 most popular data mining algorithms.
Decision trees used in data mining are of two main types:
Classification tree analysis is when the predicted outcome is the class to which the data belongs.
Regression tree analysis is when the predicted outcome can be considered a real number (e.g. the price of a house, or a patient’s length of stay in a hospital).[2]
In the previous posts I already covered how to create Regression Decision Trees with python:
Building Decision Trees in Python
Building Decision Trees in Python – Handling Categorical Data
In this post you will find more simplified python code for classification and regression decision trees. Online link to run decision tree also will be provided. This is very useful if you want see results immediately without coding.
To run the code provided here you need just change file path to file containing data. The Decision Trees in this post are tested on simple artificial dataset that was motivated by doing feature selection for blog data:
Getting Data-Driven Insights from Blog Data Analysis with Feature Selection
Dataset
Our dataset consists of 3 columns in csv file and shown below. It has 2 independent variables (features or X columns) – categorical and numerical, and dependent numerical variable (target or Y column). The script is assuming that the target column is the last column. Below is the dataset that is used in this post:
X1 X2 Y
red 1 100
red 2 99
red 1 85
red 2 100
red 1 79
red 2 100
red 1 100
red 1 85
red 2 100
red 1 79
blue 2 22
blue 1 20
blue 2 21
blue 1 13
blue 2 10
blue 1 22
blue 2 20
blue 1 21
blue 2 13
blue 1 10
blue 1 22
blue 2 20
blue 1 21
blue 2 13
blue 1 10
blue 2 22
blue 1 20
blue 2 21
blue 1 13
green 2 10
green 1 22
green 2 20
green 1 21
green 2 13
green 1 10
green 2 22
green 1 20
green 1 13
green 2 22
green 1 20
green 2 21
green 1 13
green 2 10
You can use dataset with different number of columns for independent variables without changing the code.
For converting categorical variable to numerical we use here pd.get_dummies(dataframe) method from pandas library. Here dataframe is our input data. So the column with “green”, “red”, “yellow” will be transformed in 3 columns with 0,1 values in each (one hot encoding scheme). Below are the few first rows after converting:
N X2 X1_blue X1_green X1_red Y
0 1 0.0 0.0 1.0 100
1 2 0.0 0.0 1.0 99
2 1 0.0 0.0 1.0 85
3 2 0.0 0.0 1.0 100
Python Code
Two scripts are provided here – regressor and classifier. For classifier the target variable should be categorical. We use however same dataset but convert numerical continuous variable to classes with labels (A,B,C) within the script based on inputted bin ranges ([15,50,100] which means bins 0-15, 15.001-50, 50.001-100). We use this after applying get_dummies
What if you have categorical target? Calling get_dummies will convert it to numerical too but we do not want this. In this case you need specify explicitly what columns need to be converted via parameter columns As per the documentation:
columns : list-like, default None. This is column names in the DataFrame to be encoded. If columns is None then all the columns with object or category dtype will be converted. [3]
In our example we would need to do specify column X1 like this:
dataframe=pd.get_dummies(dataframe, columns=[“X1”])
The results of running scripts are decision trees shown below:
Decision Tree Regression
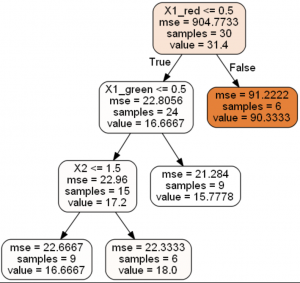
Decision Tree Classification
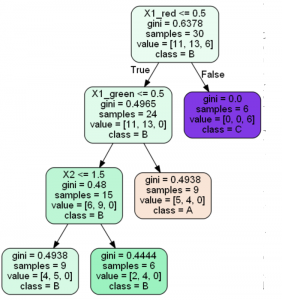
Running Decision Trees Online
In case you do not want to play with python code, you can run Decision Tree algorithms online at ML Sandbox
All that you need is just enter data into the data fields, here are the instructions:
- Go to ML Sandbox
- Select Decision Classifier OR Decision Regressor
- Enter data (first row should have headers) OR click “Load Default Values” to load the example data from this post. See screenshot below
- Click “Run Now“.
- Click “View Run Results“
- If you do not see yet data wait for a minute or so and click “Refresh Page” and you will see results
Note: your dependent variable (target variable or Y variable) should be in most right column. Also do not use space in the words (header and data)
Conclusion
Decision Trees belong to the top 10 machine learning or data mining algorithms and in this post we looked how to build Decision Trees with python. The source code provided is the end of this post. We looked also how do this if one or more columns are categorical. The source code was tested on simple categorical and numerical example and provided in this post. Alternatively you can run same algorithm online at ML Sandbox
References
1. Top 10 Machine Learning Algorithms for Beginners
2. Decision Tree Learning
3. pandas.get_dummies
Here is the python computer code of the scripts.
DecisionTreeRegressor
# -*- coding: utf-8 -*python computer code-
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.tree import DecisionTreeRegressor
import subprocess
from sklearn.tree import export_graphviz
def visualize_tree(tree, feature_names):
with open("dt.dot", 'w') as f:
export_graphviz(tree, out_file=f, feature_names=feature_names, filled=True, rounded=True )
command = ["C:\\Program Files (x86)\\Graphviz2.38\\bin\\dot.exe", "-Tpng", "C:\\Users\\Owner\\Desktop\\A\\Python_2016_A\\dt.dot", "-o", "dt.png"]
try:
subprocess.check_call(command)
except:
exit("Could not run dot, ie graphviz, to "
"produce visualization")
filename = "C:\\Users\\Owner\\Desktop\\A\\Blog Analytics\\data1.csv"
dataframe = pd.read_csv(filename, sep= ',' )
cols = dataframe.columns.tolist()
last_col_header = cols[-1]
dataframe=pd.get_dummies(dataframe)
cols = dataframe.columns.tolist()
cols.insert(len(dataframe.columns)-1, cols.pop(cols.index(last_col_header)))
dataframe = dataframe.reindex(columns= cols)
print (dataframe)
array = dataframe.values
X = array[:,0:len(dataframe.columns)-1]
Y = array[:,len(dataframe.columns)-1]
print ("--X----")
print (X)
print ("--Y----")
print (Y)
X_train, X_test, y_train, y_test = train_test_split( X, Y, test_size = 0.3, random_state = 100)
clf = DecisionTreeRegressor( random_state = 100,
max_depth=3, min_samples_leaf=4)
clf.fit(X_train, y_train)
visualize_tree(clf, dataframe.columns)
DecisionTreeClassifier
# -*- coding: utf-8 -*-
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.tree import DecisionTreeClassifier
import subprocess
from sklearn.tree import export_graphviz
def visualize_tree(tree, feature_names, class_names):
with open("dt.dot", 'w') as f:
export_graphviz(tree, out_file=f, feature_names=feature_names, filled=True, rounded=True, class_names=class_names )
command = ["C:\\Program Files (x86)\\Graphviz2.38\\bin\\dot.exe", "-Tpng", "C:\\Users\\Owner\\Desktop\\A\\Python_2016_A\\dt.dot", "-o", "dt.png"]
try:
subprocess.check_call(command)
except:
exit("Could not run dot, ie graphviz, to "
"produce visualization")
values=[15,50,100]
def convert_to_label (a):
count=0
for v in values:
if (a <= v) :
return chr(ord('A') + count)
else:
count=count+1
filename = "C:\\Users\\Owner\\Desktop\\A\\Blog Analytics\\data1.csv"
dataframe = pd.read_csv(filename, sep= ',' )
cols = dataframe.columns.tolist()
last_col_header = cols[-1]
dataframe=pd.get_dummies(dataframe)
cols = dataframe.columns.tolist()
print (dataframe)
for index, row in dataframe.iterrows():
dataframe.loc[index, "Y"] = convert_to_label(dataframe.loc[index, "Y"])
cols.insert(len(dataframe.columns)-1, cols.pop(cols.index('Y')))
dataframe = dataframe.reindex(columns= cols)
print (dataframe)
array = dataframe.values
X = array[:,0:len(dataframe.columns)-1]
Y = array[:,len(dataframe.columns)-1]
print ("--X----")
print (X)
print ("--Y----")
print (Y)
X_train, X_test, y_train, y_test = train_test_split( X, Y, test_size = 0.3, random_state = 100)
clf = DecisionTreeClassifier(criterion = "gini", random_state = 100,
max_depth=3, min_samples_leaf=4)
clf.fit(X_train, y_train)
clm=dataframe[last_col_header]
clmvalues = clm.unique()
visualize_tree(clf, dataframe.columns, clmvalues )
You must be logged in to post a comment.