Machine learning algorithms are widely used in every business – object recognition, marketing analytics, analyzing data in numerous applications to get useful insights. In this post one of machine learning techniques is applied to analysis of blog post data to predict significant features for key metrics such as page views.
You will see in this post simple example that will help to understand how to use feature selection with python code. Instructions how to quickly run online feature selection algorithm will be provided also. (no sign up is needed)
Feature Selection
In machine learning and statistics, feature selection, also known as variable selection, attribute selection or variable subset selection, is the process of selecting a subset of relevant features (variables, predictors) for use in model construction.[1]. Using feature selection we can identify most influential variables for our metrics.
The Problem – Blog Data and the Goal
For example for each post you can have the following independent variables, denoted usually X
- Number of words in the post
- Post Category (or group or topic)
- Type of post (for example: list of resources, description of algorithms )
- Year when the post was published
The list can go on.
Also for each posts there are some metrics data or dependent variables denoted by Y. Below is an example:
- Number of views
- Times on page
- Revenue $ amount associated with the page view
The goal is to identify how X impacts on Y or predict Y based on X. Knowing most significant X can provide insights on what actions need to be taken to improve Y.
In this post we will use feature selection from python ski-learn library. This technique allows to rank the features based on their influence on Y.
Example with Simple Dataset
First let’s look at artificial dataset below. It is small and only has few columns so you can see some correlation between X and Y even without running algorithm. This allows us to test the results of algorithm to confirm that it is running correctly.
X1 X2 Y
red 1 100
red 2 99
red 1 85
red 2 100
red 1 79
red 2 100
red 1 100
red 1 85
red 2 100
red 1 79
blue 2 22
blue 1 20
blue 2 21
blue 1 13
blue 2 10
blue 1 22
blue 2 20
blue 1 21
blue 2 13
blue 1 10
blue 1 22
blue 2 20
blue 1 21
blue 2 13
blue 1 10
blue 2 22
blue 1 20
blue 2 21
blue 1 13
green 2 10
green 1 22
green 2 20
green 1 21
green 2 13
green 1 10
green 2 22
green 1 20
green 1 13
green 2 22
green 1 20
green 2 21
green 1 13
green 2 10
Categorical Data
You can see from the above data that our example has categorical data (column X1) which require special treatment when we use ski-learn library. Fortunately we have function get_dummies(dataframe) that converts categorical variables to numerical using one hot encoding. After convertion instead of one column with blue, green and red we will get 3 columns with 0,1 for each color. Below is the dataset with new columns:
N X2 X1_blue X1_green X1_red Y
0 1 0.0 0.0 1.0 100
1 2 0.0 0.0 1.0 99
2 1 0.0 0.0 1.0 85
3 2 0.0 0.0 1.0 100
4 1 0.0 0.0 1.0 79
5 2 0.0 0.0 1.0 100
6 1 0.0 0.0 1.0 100
7 1 0.0 0.0 1.0 85
8 2 0.0 0.0 1.0 100
9 1 0.0 0.0 1.0 79
10 2 1.0 0.0 0.0 22
11 1 1.0 0.0 0.0 20
12 2 1.0 0.0 0.0 21
13 1 1.0 0.0 0.0 13
14 2 1.0 0.0 0.0 10
15 1 1.0 0.0 0.0 22
16 2 1.0 0.0 0.0 20
17 1 1.0 0.0 0.0 21
18 2 1.0 0.0 0.0 13
19 1 1.0 0.0 0.0 10
20 1 1.0 0.0 0.0 22
21 2 1.0 0.0 0.0 20
22 1 1.0 0.0 0.0 21
23 2 1.0 0.0 0.0 13
24 1 1.0 0.0 0.0 10
25 2 1.0 0.0 0.0 22
26 1 1.0 0.0 0.0 20
27 2 1.0 0.0 0.0 21
28 1 1.0 0.0 0.0 13
29 2 0.0 1.0 0.0 10
30 1 0.0 1.0 0.0 22
31 2 0.0 1.0 0.0 20
32 1 0.0 1.0 0.0 21
33 2 0.0 1.0 0.0 13
34 1 0.0 1.0 0.0 10
35 2 0.0 1.0 0.0 22
36 1 0.0 1.0 0.0 20
37 1 0.0 1.0 0.0 13
38 2 0.0 1.0 0.0 22
39 1 0.0 1.0 0.0 20
40 2 0.0 1.0 0.0 21
41 1 0.0 1.0 0.0 13
42 2 0.0 1.0 0.0 10
If you run python script (provided in this post) you will get feature score like below.
Columns:
X2 X1_blue X1_green X1_red
scores:
[ 0.925 5.949 4.502 33. ]
So it is showing that column with red color is most significant and this makes sense if you look at data.
How to Run Script
To run script you need put data in csv file and update filename location in the script.
Additionally you need to have dependent variable Y in most right column and it should be labeled by ‘Y’.
The script is using option ‘all’ for number of features, but you can change some number if needed.
Example with Dataset from Blog
Now we can move to actual dataset from this blog. It took a little time to prepare data but this is just for the first time. Going forward I am planning to record data regularly after I create post or at least on weekly basis. Here are the fields that I used:
- Number of words in the post – this is something that the blog is providing
- Category or group or topic – was added manually
- Type of post – I used few groups for this
- Number of views – was taken from Google Analytics
For the first time I just used data from 19 top posts.
Results
Below you can view results. The results are showing word count as significant, which could be expected, however I would think that score should be less. The results show also higher score for posts with text and code vs the posts with mostly only code (Type_textcode 10.9 vs Type_code 5.0)
Feature Score
WordsCount 2541.55769
Group_DecisionTree 18
Group_datamining 18
Group_machinelearning 18
Group_spreadsheet 18
Group_TSCNN 17
Group_python 16
Group_TextMining 12.25
Type_textcode 10.88888889
Group_API 10.66666667
Group_Visualization 9.566666667
Group_neuralnetwork 5.333333333
Type_code 5.025641026
Running Online
In case you do not want to play with python code, you can run feature selection online at ML Sandbox
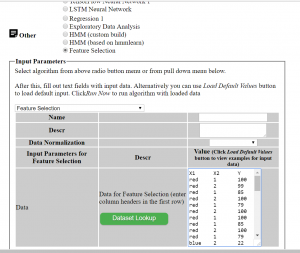
All that you need is just enter data into the data field, here are the instructions:
- Go to ML Sandbox
- Select Feature Extraction next Other
- Enter data (first row should have headers) OR click “Load Default Values” to load the example data from this post. See screenshot below
- Click “Run Now“.
- Click “View Run Results“
- If you do not see yet data wait for a minute or so and click “Refresh Page” and you will see results
Note: your dependent variable Y should be in most right column and should have header Y Also do not use space in the words (header and data)
Conclusion
In this post we looked how one of machine learning techniques – feature selection can be applied for analysis blog post data to predict significant features that can help choose better actions. We looked also how do this if one or more columns are categorical. The source code was tested on simple categorical and numerical example and provided in this post. Alternatively you can run same algorithm online at ML Sandbox
Do you run any analysis on blog data? What method do you use and how do you pull data from blog? Feel free to submit any comments or suggestions.
References
1. Feature Selection Wikipedia
2. Feature Selection For Machine Learning in Python
# -*- coding: utf-8 -*-
# Feature Extraction with Univariate Statistical Tests
import pandas
import numpy
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
filename = "C:\\Users\\Owner\\data.csv"
dataframe = pandas.read_csv(filename)
dataframe=pandas.get_dummies(dataframe)
cols = dataframe.columns.tolist()
cols.insert(len(dataframe.columns)-1, cols.pop(cols.index('Y')))
dataframe = dataframe.reindex(columns= cols)
print (dataframe)
print (len(dataframe.columns))
array = dataframe.values
X = array[:,0:len(dataframe.columns)-1]
Y = array[:,len(dataframe.columns)-1]
print ("--X----")
print (X)
print ("--Y----")
print (Y)
# feature extraction
test = SelectKBest(score_func=chi2, k="all")
fit = test.fit(X, Y)
# summarize scores
numpy.set_printoptions(precision=3)
print ("scores:")
print(fit.scores_)
for i in range (len(fit.scores_)):
print ( str(dataframe.columns.values[i]) + " " + str(fit.scores_[i]))
features = fit.transform(X)
print (list(dataframe))
numpy.set_printoptions(threshold=numpy.inf)
print ("features")
print(features)



You must be logged in to post a comment.