Doing different activities we often are interesting how they impact each other. For example, if we visit different links on Internet, we might want to know how this action impacts our motivation for doing some specific things. In other words we are interesting in inferring importance of causes for effects from our daily activities data.
In this post we will look at few ways to detect relationships between actions and results using machine learning algorithms and python.
Our data example will be artificial dataset consisting of 2 columns: URL and Y.
URL is our action and we want to know how it impacts on Y. URL can be link0, link1, link2 wich means links visited, and Y can be 0 or 1, 0 means we did not got motivated, and 1 means we got motivated.
The first thing we do hot-encoding link0, link1, link3 in 0,1 and we will get 3 columns as below. Sample of data after one hot encoding
So we have now 3 features, each for each URL. Here is the code how to do hot-encoding to prepare our data for cause and effect analysis.
Now we can apply feature extraction algorithm. It allows us select features according to the k highest scores.
# feature extraction
test = SelectKBest(score_func=chi2, k="all")
fit = test.fit(X, Y)
# summarize scores
numpy.set_printoptions(precision=3)
print ("scores:")
print(fit.scores_)
for i in range (len(fit.scores_)):
print ( str(dataframe.columns.values[i]) + " " + str(fit.scores_[i]))
features = fit.transform(X)
print (list(dataframe))
numpy.set_printoptions(threshold=numpy.inf)
scores:
[11.475 0.142 15.527]
URL_link0 11.475409836065575
URL_link1 0.14227166276346598
URL_link2 15.526957539965377
['URL_link0', 'URL_link1', 'URL_link2', 'Y']
Another algorithm that we can use is <strong>ExtraTreesClassifier</strong> from python machine learning library sklearn.
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.feature_selection import SelectFromModel
clf = ExtraTreesClassifier()
clf = clf.fit(X, Y)
print (clf.feature_importances_)
model = SelectFromModel(clf, prefit=True)
X_new = model.transform(X)
print (X_new.shape)
#output
#[0.424 0.041 0.536]
#(150, 2)
The above two machine learning algorithms helped us to estimate the importance of our features (or actions) for our Y variable. In both cases URL_link2 got highest score.
There exist other methods. I would love to hear what methods do you use and for what datasets and/or problems. Also feel free to provide feedback or comments or any questions.
Neural networks are among the most widely used machine learning techniques.[1] But neural network training and tuning multiple hyper-parameters takes time. I was recently building LSTM neural network for prediction for this post Machine Learning Stock Market Prediction with LSTM Keras and I learned some tricks that can save time. In this post you will find some techniques that helped me to do neural net training more efficiently.
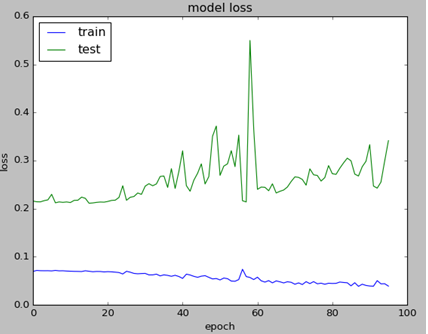
1. Adjusting Graph To See All Details
Sometimes validation loss is getting high value and this prevents from seeing other data on the chart. I added few lines of code to cut high values so you can see all details on chart.
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
T=25
history_val_loss=[]
for x in history.history['val_loss']:
if x >= T:
history_val_loss.append (T)
else:
history_val_loss.append( x )
plt.figure(6)
plt.plot(history.history['loss'])
plt.plot(history_val_loss)
plt.title('model loss adjusted')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
Below is the example of charts. Left graph is not showing any details except high value point because of the scale. Note that graphs are obtained from different tests. LSTM NN Training Value Loss Charts with High Number and Adjusted
2. Early Stopping
Early stopping is allowing to save time on not running tests when a monitored quantity has stopped improving. Here is how it can be coded:
Here is what arguments mean per Keras documentation [2].
min_delta: minimum change in the monitored quantity to qualify as an improvement, i.e. an absolute change of less than min_delta, will count as no improvement.
patience: number of epochs with no improvement after which training will be stopped.
verbose: verbosity mode.
mode: one of {auto, min, max}. In min mode, training will stop when the quantity monitored has stopped decreasing; in max mode it will stop when the quantity monitored has stopped increasing; in auto mode, the direction is automatically inferred from the name of the monitored quantity.
3. Weight Regularization
Weight regularizer can be used to regularize neural net weights. Here is the example.
I found that beta_1=0.89 performed better then suggested 0.91 or other tested values.
5. Rolling Window Size
Rolling window (in case we use it) also can impact on performance. Too small or too big will drive higher validation loss. Below are charts for different window size (N=4,8,16,18, from left to right). In this case the optimal value was 16 which resulted in 81% accuracy.
LSTM Neural Net Loss Charts with Different N
I hope you enjoyed this post on different techniques for tuning hyper parameters. If you have any tips or anything else to add, please leave a comment below in the comment box.
Below is the full source code:
import numpy as np
import pandas as pd
from sklearn import preprocessing
import matplotlib.pyplot as plt
import matplotlib.ticker as mtick
from keras.regularizers import L1L2
fname="C:\\Users\\stock data\\GM.csv"
data_csv = pd.read_csv (fname)
#how many data we will use
# (should not be more than dataset length )
data_to_use= 150
# number of training data
# should be less than data_to_use
train_end =120
total_data=len(data_csv)
#most recent data is in the end
#so need offset
start=total_data - data_to_use
yt = data_csv.iloc [start:total_data ,4] #Close price
yt_ = yt.shift (-1)
print (yt_)
data = pd.concat ([yt, yt_], axis =1)
data. columns = ['yt', 'yt_']
N=16
cols =['yt']
for i in range (N):
data['yt'+str(i)] = list(yt.shift(i+1))
cols.append ('yt'+str(i))
data = data.dropna()
data_original = data
data=data.diff()
data = data.dropna()
# target variable - closed price
# after shifting
y = data ['yt_']
x = data [cols]
scaler_x = preprocessing.MinMaxScaler ( feature_range =( -1, 1))
x = np. array (x).reshape ((len( x) ,len(cols)))
x = scaler_x.fit_transform (x)
scaler_y = preprocessing. MinMaxScaler ( feature_range =( -1, 1))
y = np.array (y).reshape ((len( y), 1))
y = scaler_y.fit_transform (y)
x_train = x [0: train_end,]
x_test = x[ train_end +1:len(x),]
y_train = y [0: train_end]
y_test = y[ train_end +1:len(y)]
x_train = x_train.reshape (x_train. shape + (1,))
x_test = x_test.reshape (x_test. shape + (1,))
from keras.models import Sequential
from keras.layers.core import Dense
from keras.layers.recurrent import LSTM
from keras.layers import Dropout
from keras import optimizers
from numpy.random import seed
seed(1)
from tensorflow import set_random_seed
set_random_seed(2)
from keras import regularizers
from keras.callbacks import EarlyStopping
earlystop = EarlyStopping(monitor='val_loss', min_delta=0.0001, patience=80, verbose=1, mode='min')
callbacks_list = [earlystop]
model = Sequential ()
model.add (LSTM ( 400, activation = 'relu', inner_activation = 'hard_sigmoid' , bias_regularizer=L1L2(l1=0.01, l2=0.01), input_shape =(len(cols), 1), return_sequences = False ))
model.add(Dropout(0.3))
model.add (Dense (output_dim =1, activation = 'linear', activity_regularizer=regularizers.l1(0.01)))
adam=optimizers.Adam(lr=0.01, beta_1=0.89, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=True)
model.compile (loss ="mean_squared_error" , optimizer = "adam")
history=model.fit (x_train, y_train, batch_size =1, nb_epoch =1000, shuffle = False, validation_split=0.15, callbacks=callbacks_list)
y_train_back=scaler_y.inverse_transform (np. array (y_train). reshape ((len( y_train), 1)))
plt.figure(1)
plt.plot (y_train_back)
fmt = '%.1f'
tick = mtick.FormatStrFormatter(fmt)
ax = plt.axes()
ax.yaxis.set_major_formatter(tick)
print (model.summary())
print(history.history.keys())
T=25
history_val_loss=[]
for x in history.history['val_loss']:
if x >= T:
history_val_loss.append (T)
else:
history_val_loss.append( x )
plt.figure(2)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
fmt = '%.1f'
tick = mtick.FormatStrFormatter(fmt)
ax = plt.axes()
ax.yaxis.set_major_formatter(tick)
plt.figure(6)
plt.plot(history.history['loss'])
plt.plot(history_val_loss)
plt.title('model loss adjusted')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
score_train = model.evaluate (x_train, y_train, batch_size =1)
score_test = model.evaluate (x_test, y_test, batch_size =1)
print (" in train MSE = ", round( score_train ,4))
print (" in test MSE = ", score_test )
pred1 = model.predict (x_test)
pred1 = scaler_y.inverse_transform (np. array (pred1). reshape ((len( pred1), 1)))
prediction_data = pred1[-1]
model.summary()
print ("Inputs: {}".format(model.input_shape))
print ("Outputs: {}".format(model.output_shape))
print ("Actual input: {}".format(x_test.shape))
print ("Actual output: {}".format(y_test.shape))
print ("prediction data:")
print (prediction_data)
y_test = scaler_y.inverse_transform (np. array (y_test). reshape ((len( y_test), 1)))
print ("y_test:")
print (y_test)
act_data = np.array([row[0] for row in y_test])
fmt = '%.1f'
tick = mtick.FormatStrFormatter(fmt)
ax = plt.axes()
ax.yaxis.set_major_formatter(tick)
plt.figure(3)
plt.plot( y_test, label="actual")
plt.plot(pred1, label="predictions")
print ("act_data:")
print (act_data)
print ("pred1:")
print (pred1)
plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.05),
fancybox=True, shadow=True, ncol=2)
fmt = '$%.1f'
tick = mtick.FormatStrFormatter(fmt)
ax = plt.axes()
ax.yaxis.set_major_formatter(tick)
def moving_test_window_preds(n_future_preds):
''' n_future_preds - Represents the number of future predictions we want to make
This coincides with the number of windows that we will move forward
on the test data
'''
preds_moving = [] # Store the prediction made on each test window
moving_test_window = [x_test[0,:].tolist()] # First test window
moving_test_window = np.array(moving_test_window)
for i in range(n_future_preds):
preds_one_step = model.predict(moving_test_window)
preds_moving.append(preds_one_step[0,0])
preds_one_step = preds_one_step.reshape(1,1,1)
moving_test_window = np.concatenate((moving_test_window[:,1:,:], preds_one_step), axis=1) # new moving test window, where the first element from the window has been removed and the prediction has been appended to the end
print ("pred moving before scaling:")
print (preds_moving)
preds_moving = scaler_y.inverse_transform((np.array(preds_moving)).reshape(-1, 1))
print ("pred moving after scaling:")
print (preds_moving)
return preds_moving
print ("do moving test predictions for next 22 days:")
preds_moving = moving_test_window_preds(22)
count_correct=0
error =0
for i in range (len(y_test)):
error=error + ((y_test[i]-preds_moving[i])**2) / y_test[i]
if y_test[i] >=0 and preds_moving[i] >=0 :
count_correct=count_correct+1
if y_test[i] < 0 and preds_moving[i] < 0 :
count_correct=count_correct+1
accuracy_in_change = count_correct / (len(y_test) )
plt.figure(4)
plt.title("Forecast vs Actual, (data is differenced)")
plt.plot(preds_moving, label="predictions")
plt.plot(y_test, label="actual")
plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.05),
fancybox=True, shadow=True, ncol=2)
print ("accuracy_in_change:")
print (accuracy_in_change)
ind=data_original.index.values[0] + data_original.shape[0] -len(y_test)-1
prev_starting_price = data_original.loc[ind,"yt_"]
preds_moving_before_diff = [0 for x in range(len(preds_moving))]
for i in range (len(preds_moving)):
if (i==0):
preds_moving_before_diff[i]=prev_starting_price + preds_moving[i]
else:
preds_moving_before_diff[i]=preds_moving_before_diff[i-1]+preds_moving[i]
y_test_before_diff = [0 for x in range(len(y_test))]
for i in range (len(y_test)):
if (i==0):
y_test_before_diff[i]=prev_starting_price + y_test[i]
else:
y_test_before_diff[i]=y_test_before_diff[i-1]+y_test[i]
plt.figure(5)
plt.title("Forecast vs Actual (non differenced data)")
plt.plot(preds_moving_before_diff, label="predictions")
plt.plot(y_test_before_diff, label="actual")
plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.05),
fancybox=True, shadow=True, ncol=2)
plt.show()
In this post I will share experiments on machine learning stock prediction with LSTM and Keras with one step ahead. I tried to do first multiple steps ahead with few techniques described in the papers on the web. But I discovered that I need fully understand and test the simplest model – prediction for one step ahead. So I put here the example of prediction of stock price data time series for one next step.
Preparing Data for Neural Network Prediction
Our first task is feed the data into LSTM. Our data is stock price data time series that were downloaded from the web.
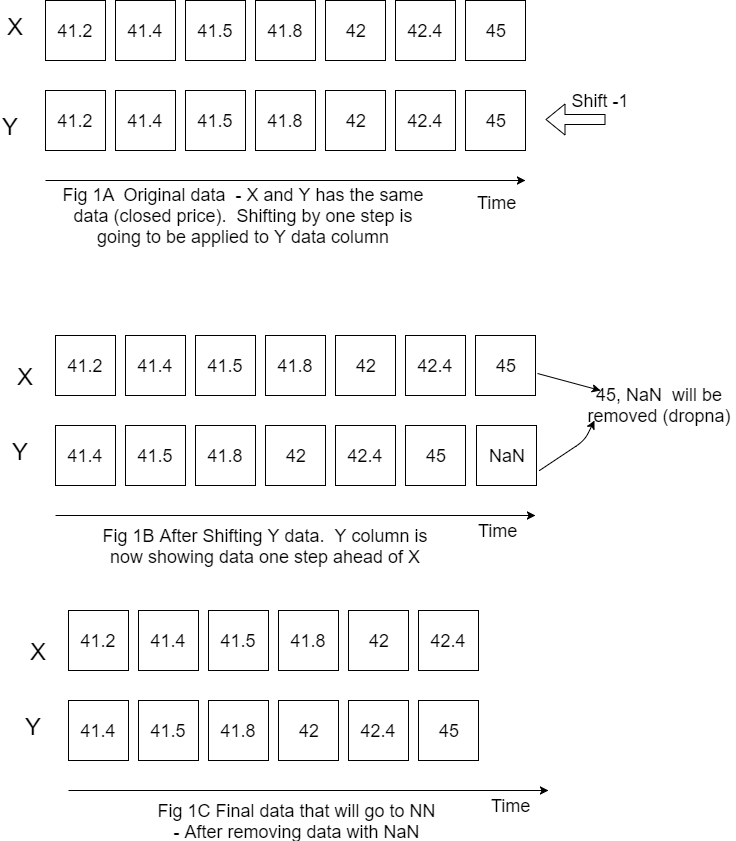
Our interest is closed price for the next day so target variable will be closed price but shifted to left (back) by one step.
Figure below is showing how do we prepare X, Y data.
Please note that I put X Y horizontally for convenience but still calling X, Y as columns.
Also on this figure only one variable (closed price) is showed for X but in the code it is actually more than one variable (it is closed price, open price, volume and high price).
LSTM data input
Now we have the data that we can feed for LSTM neural network prediction. Before doing this we need also do the following things:
1. Decide how many data we want to use. For example if we have data for 10 years but want use only last 200 rows of data we would need specify start point because the most recent data will be in the end.
#how many data we will use
# (should not be more than dataset length )
data_to_use= 100
# number of training data
# should be less than data_to_use
train_end =70
total_data=len(data_csv)
#most recent data is in the end
#so need offset
start=total_data - data_to_use
2. Rescale (normalize) data as below. Here feature_range is tuple (min, max), default=(0, 1) is desired range of transformed data. [1]
scaler_x = preprocessing.MinMaxScaler ( feature_range =( -1, 1))
x = np. array (x).reshape ((len( x) ,len(cols)))
x = scaler_x.fit_transform (x)
scaler_y = preprocessing. MinMaxScaler ( feature_range =( -1, 1))
y = np.array (y).reshape ((len( y), 1))
y = scaler_y.fit_transform (y)
3. Divide data into training and testing set.
x_train = x [0: train_end,]
x_test = x[ train_end +1:len(x),]
y_train = y [0: train_end]
y_test = y[ train_end +1:len(y)]
Building and Running LSTM
Now we need to define our LSTM neural network layers , parameters and run neural network to see how it works.
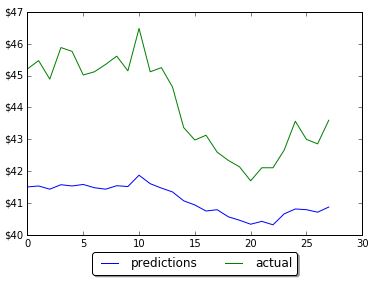
The first run was not good – prediction was way below actual.
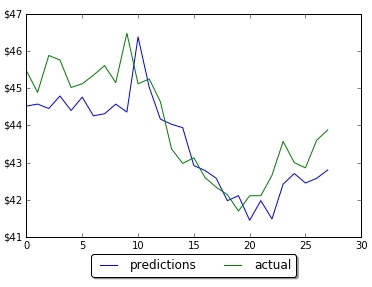
However by changing the number of neurons in LSTM neural network prediction code, it was possible to improve MSE and get predictions much closer to actual data. Below are screenshots of plots of prediction and actual data for LSTM with 5, 60 and 1000 neurons. Note that the plot is showing only testing data. Training data is not shown on the plots. Also you can find below the data for MSE and number of neurons. As the number neorons in LSTM layer is changing there were 2 minimums (one around 100 neurons and another around 1000 neurons)
Results of prediction on LSTM with 5 neuronsResults of prediction on LSTM with 60 neuronsResults of prediction on LSTM with 1000 neurons
LSTM 5
in train MSE = 0.0475
in test MSE = 0.2714831660102521
LSTM 60
in train MSE = 0.0127
in test MSE = 0.02227417068206705
LSTM 100
in train MSE = 0.0126
in test MSE = 0.018672733913263073
LSTM 200
in train MSE = 0.0133
in test MSE = 0.020082660237026824
LSTM 900
in train MSE = 0.0103
in test MSE = 0.015546535929778267
LSTM 1000
in train MSE = 0.0104
in test MSE = 0.015037054958075455
LSTM 1100
in train MSE = 0.0113
in test MSE = 0.016363980411369994
Conclusion
The final LSTM was running with testing MSE 0.015 and accuracy 97%. This was obtained by changing number of neurons in LSTM. This example will serve as baseline for further possible improvements on machine learning stock prediction with LSTM. If you have any tips or anything else to add, please leave a comment the comment box. The full source code for LSTM neural network prediction can be found here
In the previous post I showed how to use the Prophet for time series analysis with python. I used Prophet for data stock price prediction. But it was used only for one stock and only for next 10 days.
In this post we will select more data and will test how accurate can be prediction data stock prices with Prophet.
We will select 5 stocks and will do prediction stock prices based on their historical data. You will get chance to look at the report how error is distributed across different stocks or number of days in forecast. The summary report will show that we can easy get accuracy as high as 96.8% for stock price prediction with Prophet for 20 days forecast.
Data and Parameters
The five stocks that we will select are the stocks in the price range between $20 – $50. The daily historical data are taken from the web.
For time horizon we will use 20 days. That means that we will save last 20 prices for testing and will not use for forecasting.
Experiment
For this experiment we use python script with the main loop that is iterating for each stock. Inside of the loop, Prophet is doing forecast and then error is calculated and saved for each day in forecast:
model = Prophet() #instantiate Prophet
model.fit(data);
future_stock_data = model.make_future_dataframe(periods=steps_ahead, freq = 'd')
forecast_data = model.predict(future_stock_data)
step_count=0
# save actual data
for index, row in data_test.iterrows():
results[ind][step_count][0] = row['y']
results[ind][step_count][4] = row['ds']
step_count=step_count + 1
# save predicted data and calculate error
count_index = 0
for index, row in forecast_data.iterrows():
if count_index >= len(data) :
step_count= count_index - len(data)
results[ind][step_count][1] = row['yhat']
results[ind][step_count][2] = results[ind][step_count][0] - results[ind][step_count][1]
results[ind][step_count][3] = 100 * results[ind][step_count][2] / results[ind][step_count][0]
count_index=count_index + 1
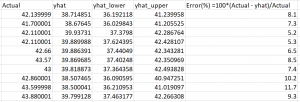
Later on (as shown in the above python source code) we count error as difference between actual closed price and predicted. Also error is calculated in % for each day for each stock using the formula:
Error(%) = 100*(Actual-Predicted)/Actual
Results
The detailed result report can be found here. In this report you can see how error is distributed across different days. You can note that there is no significant increase in error with 20 days of forecast and the error always has the same sign for all 20 days.
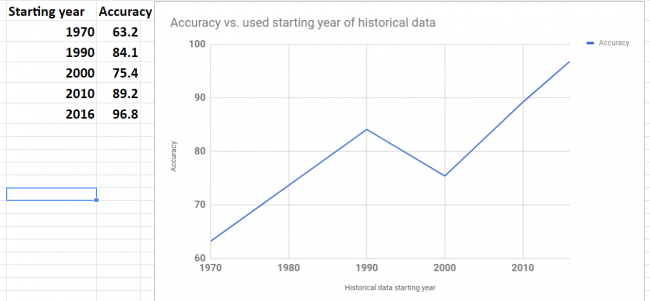
Below is the summary of error and accuracy for our selected 5 stocks. Also added the column the year of starting point of data range that was used for forecast. It turn out that all 5 stocks have different historical data range. The shortest data range was starting in the middle of 2016.
prediction data stock prices with Prophet summary of results
Overall results for accuracy are not great. Only one stock got good accuracy 96.8%.
Accuracy was varying for different stocks. To investigate variation I plot graph of accuracy and beginning year of historical data. The plot is shown below. Looks like there is a correlation between data range used for forecast and accuracy. This makes sense – as the data in the further past may be do more harm than good.
Looking at the plot below we see that the shortest historical range (just about for one year) showed the best accuracy.
prediction data stock prices with Prophet – accuracy vs used data range
Conclusion
We did not get good results (except one stock) in our experiments but we got the knowledge about possible range and distribution of error over the different stocks and time horizon (up to 20 days). Also it looks promising to try do forecast with different historical data range to check how it will affect performance. It would be interesting to see if the best accuracy that we got for one stock can be achieved for other stocks too.
I hope you enjoyed this post about using Prophet for prediction data stock prices. If you have any tips or anything else to add, please leave a comment in the reply box below.
Here is the script for stock data forecasting with python using Prophet.
import pandas as pd
from fbprophet import Prophet
steps_ahead = 20
fname_path="C:\\Users\\stock data folder"
fnames=['fn1.csv','fn2.csv', 'fn3.csv', 'fn4.csv', 'fn5.csv']
# output fields: actual, predicted, error, error in %, date
fields_number = 6
results= [[[0 for i in range(len(fnames))] for j in range(steps_ahead)] for k in range(fields_number)]
for ind in range(5):
fname=fname_path + "\\" + fnames[ind]
data = pd.read_csv (fname)
#keep only date and close
#delete Open, High, Low , Adj CLose, Volume
data.drop(data.columns[[1, 2, 3,5,6]], axis=1)
data.columns = ['ds', 'y', "", "", "", "", ""]
data_test = data[-steps_ahead:]
print (data_test)
data = data[:-steps_ahead]
print (data)
model = Prophet() #instantiate Prophet
model.fit(data);
future_stock_data = model.make_future_dataframe(periods=steps_ahead, freq = 'd')
forecast_data = model.predict(future_stock_data)
print (forecast_data[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(12))
step_count=0
for index, row in data_test.iterrows():
results[ind][step_count][0] = row['y']
results[ind][step_count][4] = row['ds']
step_count=step_count + 1
count_index = 0
for index, row in forecast_data.iterrows():
if count_index >= len(data) :
step_count= count_index - len(data)
results[ind][step_count][1] = row['yhat']
results[ind][step_count][2] = results[ind][step_count][0] - results[ind][step_count][1]
results[ind][step_count][3] = 100 * results[ind][step_count][2] / results[ind][step_count][0]
count_index=count_index + 1
for z in range (5):
for i in range (steps_ahead):
temp=""
for j in range (5):
temp=temp + " " + str(results[z][i][j])
print (temp)
print (z)
Recently Facebook released Prophet – open source software tool for forecasting time series data.
Facebook team have implemented in Prophet two trend models that can cover many applications: a saturating growth model, and a piecewise linear model. [4]
With growth model Prophet can be used for prediction growth/decay – for example for modeling growth of population or website traffic. By default, Prophet uses a linear model for its forecast.
In this post we review main features of Prophet and will test it on prediction of stock data prices for next 10 business days. We will use python for time series programming with Prophet.
How to Use Prophet for Time Series Analysis with Python
Here is the minimal python source code to create forecast with Prophet.
import pandas as pd
from fbprophet import Prophet
The input columns should have headers as ‘ds’ and ‘y’. In the code below we run forecast for 180 days ahead for stock data, ds is our date stamp data column, and y is actual time series column
fname="C:\\Users\\data analysis\\gm.csv"
data = pd.read_csv (fname)
data.columns = ['ds', 'y']
model = Prophet()
model.fit(data); #fit the model
future_stock_data = model.make_future_dataframe(periods=180, freq = 'd')
forecast_data = model.predict(future_stock_data)
print ("Forecast data")
model.plot(forecast_data)
The result of the above code will be graph shown below. time series analysis python using Prophet
Time series model consists of three main model components: trend, seasonality, and holidays.
We can print components using the following line
model.plot_components(forecast_data)
time series analysis python – components
Can Prophet be Used for Data Stock Price Prediction?
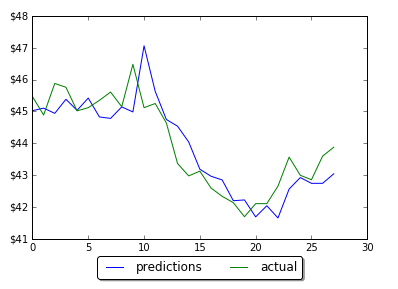
It is interesting to know if Prophet can be use for financial market price forecasting. The practical question is how accurate forecasting with Prophet for stock data prices? Data analytics for stock market is known as hard problem as many different events influence stock prices every day. To check how it works I made forecast for 10 days ahead using actual stock data and then compared Prophet forecast with actual data.
The error was calculated for each day for data stock price (closed price) and is shown below Data stock price prediction analysis
Based on obtained results the average error is 7.9% ( this is 92% accuracy). In other words the accuracy is sort of low for stock prices prediction. But note that all errors have the same sign. May be Prophet can be used better for prediction stock market direction? This was already mentioned in another blog [2].
And also looks like the error is not changing much with the the time horizon, at least within first 10 steps. Forecasts for days 3,4,5 even have smaller error than for the day 1 and 2.
Further looking at more data would be interesting and will follow soon. Bellow is the full python source code.
import pandas as pd
from fbprophet import Prophet
fname="C:\\Users\\GM.csv"
data = pd.read_csv (fname)
data.columns = ['ds', 'y']
model = Prophet() #instantiate Prophet
model.fit(data); #fit the model with your dataframe
future_stock_data = model.make_future_dataframe(periods=10, freq = 'd')
forecast_data = model.predict(future_stock_data)
print ("Forecast data")
print (forecast_data[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(12))
model.plot(forecast_data)
model.plot_components(forecast_data)







You must be logged in to post a comment.